CosmosDB for MongoDB & Semantic Searching
Author: Developer Relations, 14 May 2024
Overview
An overall good resource to understand vector searches in CosmosDB is https://learn.microsoft.com/en-us/azure/cosmos-db/mongodb/vcore/vector-search
The content in this document is based heavily on Jonathan Scholtes’ excellent articles found at https://stochasticcoder.com/author/jscholtes128/ Check them out sometime. Specifically for our walkthrough purposes we reference the content at https://stochasticcoder.com/2024/03/08/azure-cosmos-db-for-mongodb-hnsw-vector-search. That page mentions
“To make use of the HNSW vector index with Azure Cosmos DB, it is necessary to enable the “mongoHnswIndex” preview feature. “
As of 9 May 2024 we did not find that to be the case.
That article also uses data from Rocket_Propulsion_Data.zip. In our example, we are using movie data.from the 2020s which was obtained from https://github.com/prust/wikipedia-movie-data/blob/master/movies-2020s.json
The movie data loaded here will be used in the second part of this CosmosDB and GenAI series as the retrieved data for a Qarbine GenAI based interactive analysis report example.
Reminders
As of 9 May 2024 the Microsoft page at https://learn.microsoft.com/en-us/azure/cosmos-db/mongodb/vcore/vector-search states “You can create (Hierarchical Navigable Small World) indexes on M40 cluster tiers and higher.” That size costs just over $300 per month and there is also no option to pause its operation. So, you may want to create it in its own resource group and later carefully delete that resource group once you have done your interactions.
Compared to inverted file (IVF) indexes which use clusters to approximate nearest-neighbor search, HNSW uses proximity graphs (graphs connecting nodes based on distance between them). This walkthrough example uses the latter.
Prerequisites
An Azure account is required. You can create a free one at https://azure.microsoft.com/free
An Azure Cosmos DB for MongoDB (vCore) is required. The suggestion is to create it in its own resource group. When you search for resources to create, enter “azure cosmos db for Mongodb”. You can create the CosmosDB resource by following the quick start at https://learn.microsoft.com/en-us/azure/cosmos-db/mongodb/vcore/quickstart-portal In that blog the snapshot from August 2023 shows “Preview” but that is no longer the case.
On the resource creation’s Basics tab, be sure to click
Be sure to uncheck
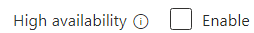
On the resulting page, be sure the cluster tier is at least an M40 to support HNSW.
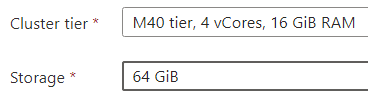
Note the monthly cost to the right for this resource!
To cut the default pricing in half, check
And check

At the bottom of the page click

Also on the Basics page remember your database user and password credentials.
On the Networking page be sure to click

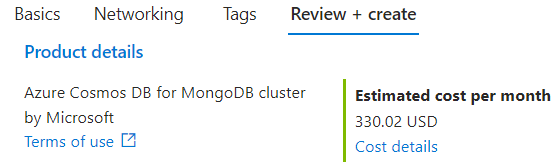
On the Review and Create page not the costs. For this walkthrough you will likely not be leaving the resource running for that long.
Click
and patiently wait for the CosmosDB for MongoDB (vcore) resource to be created. It takes about 10 minutes 😉 While you are waiting, familiarize yourself with the next sections, but do wait for the resource to be deployed.
When your deployment is complete, click
In the left hand gutter click

A connection string will be listed. On the far right click

Paste the text somewhere and edit the user and password values to those used during resource creation above.
Python Code Setup
This step is modeled after “Setting Up Python” section found at
Create a .env file to hold onto your sensitive environment variables. its contents look like,
OPENAI_API_KEY=”**Your Open AI Key**”
MONGO_CONNECTION_STRING=”mongodb+srv:**your connection string from Azure Cosmos DB**”
Loading the Data
You have the option to load data with predefined embeddings or use python to load the data and calculate the embedding values. For the latter an OpenAI account is required. See the following for details https://platform.openai.com/docs/overview
Option 1) Loading Predefined Movie Data with Embeddings
For this walkthrough after the CosmosDB for MongoDB (vcore) instance is started, you can load the data with the embeddings predefined instead of loading and computing the embeddings. That file is located at
The single line command is shown wrapped below
mongorestore –drop –uri “mongodb+srv://<User>:<Password>@<ClusterName>.cosmos.azure.com/ ?tls=true&authMechanism=SCRAM-SHA-256” –archive=2024_05_09_vcore.bson
If you copy the above text then check for an extra space in front of the ‘?’ character.
2024-05-14T00:04:33 WARNING: ignoring unsupported URI parameter 'tls'
2024-05-14T00:04:34 preparing collections to restore from
2024-05-14T00:04:34 reading metadata for demo.movies2020 from archive '2024_05_09_vcore.bson'
2024-05-14T00:04:35 restoring demo.movies2020 from archive '2024_05_09_vcore.bson'
2024-05-14T00:04:37 demo.movies2020 20.2MB
2024-05-14T00:04:40 demo.movies2020 20.2MB
2024-05-14T00:04:43 demo.movies2020 20.2MB
2024-05-14T00:04:43 demo.movies2020 21.4MB
2024-05-14T00:04:43 restoring indexes for collection demo.movies2020 from metadata
2024-05-14T00:04:44 finished restoring demo.movies2020 (267 documents, 0 failures)
2024-05-14T00:04:44 267 document(s) restored successfully. 0 document(s) failed to restore.
Option 2) Load the Movie Data and Computing the Embeddings
Remember this option requires an OpenAI subscription and its API key must be in the .env file noted above. The OpenAI subscription is needed to calculate the embeddings. See https://platform.openai.com/docs/overview
To try out the python loading code, download the 2020 movies data from https://qarbine.com/wp-content/uploads/2024/05/movies-2020s-ansii.zip
The full movie download was about 21 MB so this subset of about 1 MB was created for the purpose of experimenting.
Next, create a Python file called jsonloader.py to support the loading of the movie data. It includes some sanity checks on the data for our data loading example. It is modeled after
import json
from pathlib import Path
from typing import List, Optional, Union
import uuid
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
class JSONLoader(BaseLoader):
def __init__(
self,
file_path: Union[str, Path]
):
self.file_path = Path(file_path).resolve()
def load(self) -> List[Document]:
"""Load and return documents from the JSON file."""
docs:List[Document]=[]
# Open JSON file
with open(self.file_path) as file:
data = json.load(file)
counter = 1
#iterate through resource pages and create a Document for each page
for page in data:
#print(counter)
counter = counter + 1
extract = page.get('extract')
if extract== None :
continue;
thumbnail = page.get('thumbnail')
if thumbnail == None :
continue;
print(counter, 'Insert')
title = page['title']
year = page['year']
cast = page['cast']
genres = page['genres']
href = page['href']
metadata = dict(
title=title,
year=year,
cast=cast,
genres=genres,
thumbnail=thumbnail,
href=href
)
docs.append(Document(page_content=extract, metadata=metadata))
return docs
Next create the file movieLoader.py. It loads the JSON data from the file into the movies2020 collection within the demo database. It also populates the embedding field named “embedding” to hold on the array of numbers and defines an index named “vectorSearchIndex. These values are in the hard coded area as noted below.
from os import environ
from pathlib import Path
from typing import List, Optional, Union
from dotenv import load_dotenv
from pymongo import MongoClient
from jsonloader import JSONLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores.azure_cosmos_db import AzureCosmosDBVectorSearch, CosmosDBSimilarityType,CosmosDBVectorSearchType
load_dotenv(override=True)
class CosmosDBLoader():
def __init__(
self,
file_path: Union[str, Path],
enable_HNSW:bool=False):
self.file_path = Path(file_path).resolve()
self.enable_HNSW = enable_HNSW
def load(self):
"""load embeddings from file_path into cosmosDB vector store"""
#variable from '.env' file
OPENAI_API_KEY = environ.get("OPENAI_API_KEY")
MONGO_CONNECTION_STRING = environ.get("MONGO_CONNECTION_STRING")
#hardcoded variables
DB_NAME = "demo"
COLLECTION_NAME = "movies2020"
EMBEDDING_FIELD_NAME = "embedding"
INDEX_NAME = "vectorSearchIndex"
client = MongoClient(MONGO_CONNECTION_STRING)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
loader = JSONLoader(self.file_path )
docs = loader.load()
#load documents into Cosmos DB Vector Store
vector_store = AzureCosmosDBVectorSearch.from_documents(
docs,
OpenAIEmbeddings(disallowed_special=()),
collection=collection,
index_name=INDEX_NAME)
if vector_store.index_exists() == False:
#Create an index for vector search
num_lists = 1 #for a small demo, you can start with numLists set to 1 to perform a brute-force search across all vectors.
dimensions = 1536
if self.enable_HNSW:
print('VECTOR_HNSW')
# m= 16 is default; higher value is suitable for datasets with high dimensionality and/or high accuracy requirements
# ef_construction= 64 is default; Higher value will result in better index quality and higher accuracy, but it will also increase the time required to build the index.
vector_store.create_index(similarity =CosmosDBSimilarityType.COS,
kind=CosmosDBVectorSearchType.VECTOR_HNSW ,
m=16,
ef_construction=64,
dimensions=dimensions)
else:
print('VECTOR_IVF')
vector_store.create_index(kind=CosmosDBVectorSearchType.VECTOR_IVF ,
num_lists=num_lists,
dimensions=dimensions,
similarity =CosmosDBSimilarityType.COS)
CosmosDBLoader("movies-2020s-ansii.json",enable_HNSW=True).load()
Load the movie data by running
python movieLoader.py
Searching the Movies
The python code for semantically searching the movies is defined in search.py. Its contents are shown below with the search query of “dracula horror”. Change it as you see fit for your testing and experimentation.
from os import environ
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores.azure_cosmos_db import AzureCosmosDBVectorSearch
import time
load_dotenv(override=True)
#variable from '.env' file
MONGO_CONNECTION_STRING = environ.get("MONGO_CONNECTION_STRING")
#hardcoded variables
DB_NAME = "demo"
COLLECTION_NAME = "movies2020"
INDEX_NAME = "vectorSearchIndex"
#connect to Azure Cosmos DB for vector search
vector_store = AzureCosmosDBVectorSearch.from_connection_string(MONGO_CONNECTION_STRING,
DB_NAME + "." + COLLECTION_NAME,
OpenAIEmbeddings(disallowed_special=()),
index_name=INDEX_NAME )
start_time = time.time()
#query to use in similarity_search
query = "dracula horror"
docs = vector_store.similarity_search(query,k=10)
#format results from search
for doc in docs:
# print(doc)
print({ 'title':doc.metadata["title"],
'content':doc.page_content})
print(f"--- {time.time() - start_time:.2f} seconds ---")
Run
python search.py
Sample output is shown below.
C:\Users\someone\AppData\Roaming\Python\Python312\site-packages\langchain_community\vectorstores\azure_cosmos_db.py:145: UserWarning: You appear to be connected to a CosmosDB cluster. For more information regarding feature compatibility and support please visit https://www.mongodb.com/supportability/cosmosdb
client: MongoClient = MongoClient(connection_string, appname=appname)
{'title': 'Renfield', 'content': "Renfield is a 2023 American supernatural comedy horror film directed and co-produced by Chris McKay and written by Ryan Ridley from an original idea by Robert Kirkman…"}
{'title': 'Vampires vs. the Bronx', 'content': 'Vampires vs. the Bronx is a 2020 American comedy horror film directed by Oz Rodriguez and written by Oz Rodriguez and Blaise Hemingway. Vampires vs. the Bronx….'}
{'title': 'Hotel Transylvania: Transformania', 'content': 'Hotel Transylvania: Transformania is a 2022 American computer-animated adventure comedy film produced by Columbia Pictures and Sony Pictures Animation and released by Amazon Studios. The fourth and final installment in the Hotel Transylvania franchise and the sequel to Hotel Transylvania 3: Summer Vacation (2018)...'}
{'title': 'Hellraiser', 'content': "Hellraiser is a 2022 supernatural horror film directed by David Bruckner, with a screenplay by Ben Collins and Luke Piotrowski, from a screen story they co-wrote with David S. Goyer. It is a reboot of the Hellraiser franchise, the eleventh installment overall, and a second adaptation of the 1986 novella The Hellbound Heart by Clive Barker, which was adapted into the 1987 film Hellraiser…"}
Cleanup
Congratulations, you have used semantic searches for a new way to perform data retrievals in CosmosDB for MongoDB (vcore) If you have created a resource group to hold onto your CosmosDB for MongoDB (vCore) then carefully remove it now. If you just want to delete the CosmosDB for MongoDB (vCore) resource instead then locate that resource. Carefully review things, and, once satisfied, click Delete.
Note that while the confirmation prompt text shows “Account Name”, we found that the correct answer is the name of the CosmosDB resource instead and nothing to do with your “account” per se.